Document Actions
Lecture et mesure de temps de reconnaissance des mots
Frédérique Cordier, Valérie Fontanieu et Réjane Monod-Ansaldi
Introduction :
La variabilité est une des caractéristiques du vivant qui est peu prise en compte dans les expérimentations menées avec les élèves en classe de SVT. Pourtant, les grandeurs étudiées en biologie au collège et au lycée sont souvent des grandeurs variables dans le temps chez un même individu (pression artérielle, testostéronémie…), ou variables d’un individu à l’autre dans une population (taille, masse, vitesse de croissance…). Le peu de temps disponible pour manipuler conduit souvent à proposer aux élèves de ne réaliser qu’une seule mesure de ces grandeurs (à un seul moment, sur un seul individu), sans prendre en charge, ni même expliciter, leur variabilité. Les conclusions inductives tirées de ces expériences masquent la complexité du vivant et de l’approche expérimentale en biologie. Lorsque plusieurs mesures sont réalisées, les résultats chiffrés constituent des séries de données qu’élèves et professeurs peinent à analyser. Le cas le plus fréquent correspond à deux séries de données obtenues dans deux conditions ne différant que par un seul facteur, dont on veut tester l’influence sur la grandeur mesurée. Comment conclure ? Quels outils mathématiques utiliser ?
C’est la statistique qui fournit aux biologistes des instruments pour aborder l’étude de grandeurs et de phénomènes variables (Girault et Girault, 2004), mais son approche par les élèves et par les enseignants n’est pas aisée. Pourtant, l’importance de l’éducation à la pensée probabiliste est soulignée par les programmes d’enseignement, tels que l’introduction commune aux disciplines scientifiques et technologiques des programmes d’enseignement de collège qui consacre son premier thème de convergence à « l’importance du mode de pensée statistique dans le regard scientifique sur le monde » (BO spécial n°6, 28 août 2008, p5). Nous nous sommes donc engagées dans l’étude de la prise en compte de la variabilité du vivant dans l’expérimentation au collège et au lycée, en expérimentant des situations permettant aux élèves de se confronter à cet aspect de la biologie, dans le but de produire des ressources et des outils statistiques pour les enseignants. Plusieurs expérimentations focalisées sur le temps de réaction ont été menées au sein de l’équipe ACCES de l’IFE. Cette page présente un travail sur la reconnaissance de mots, réalisé en 2011-2012 au sein de l'équipe EducTice, avec des élèves de première L et première S du Lycée Albert Camus à Rillieux la Pape.
Sommaire
1- Contexte et objectifs de la séquence d'enseignement expérimentée
2- Séance expérimentée en première L
3- Séance expérimentée en première S
4- Approche statistique de l'étude du temps de reconnaissance de mots et non-mots
1- Contexte et objectifs de la séquence d’enseignement expérimentée
- Les textes officiels du programme de première S (BO n°9, 30 septembre 2013) précisent :
« Plusieurs aires corticales participent à la vision. L’imagerie fonctionnelle du cerveau permet d’observer leur activation lorsque l’on observe des formes, des mouvements. La reconnaissance des formes nécessite une collaboration entre les fonctions visuelles et la mémoire. (…) La mise en place du phénotype fonctionnel du système cérébral impliqué dans la vision repose sur des structures cérébrales innées, issues de l’évolution et sur la plasticité cérébrale au cours de l’histoire personnelle. De même la mémoire nécessaire par exemple à la reconnaissance d’un visage ou d’un mot repose sur la plasticité du cerveau. L’apprentissage repose sur la plasticité cérébrale. Il nécessite la sollicitation répétée des mêmes circuits neuroniques. »
La séance proposée permet à la fois d'expérimenter pour répondre à cette partie de programme et de travailler en transversalité en mathématiques et SVT.
- Le thème sur la vision du monde est par ailleurs commun aux 1ères L et ES. Le thème de l’apprentissage de la lecture a donc été privilégié dans l'intérêt de toutes les premières, y compris non scientifiques. Ce thème s’ancre effectivement dans le vécu de chaque élève et reste un sujet vif d’un point de vue scientifique.
- L’idée de la séquence expérimentée est la suivante : mettre en évidence l’acquisition cérébrale de la capacité à reconnaître des mots, en mesurant le temps mis pour reconnaître soit deux mots identiques, soit deux chaînes de consonnes identiques de six lettres à chaque fois. En effet, si notre cerveau a acquis la capacité à reconnaître les mots, le temps de reconnaissance doit être plus court pour les mots que pour les chaînes de consonnes.
- Le logiciel Réaction mis au point par François Tilquin pour l’INRP-IFE est un outil qui permet de créer des tests variés impliquant une reconnaissance visuelle. Il est alors facilement utilisable pour les élèves. Les tests utilisés ici sont des tests de comparaison : l’élève doit reconnaître deux images identiques, soit des mots soit des chaînes de consonnes de 6 lettres. Le logiciel mesure le temps mis à reconnaître l’identité et à réagir en appuyant sur la touche Entrée : on parlera de temps de reconnaissance / réaction ou plus simplement de temps de réponse.
Le résultat des mesures se présente sous la forme d’un tableau de mesure exploitable sous Excel.
2 – Séance
expérimentée en première L
- La séance s’est déroulée sur 1H30 durant laquelle les élèves ont travaillé sur un problème imposé : L’apprentissage de la lecture modifie-t-il le fonctionnement de notre cerveau ?
Une hypothèse a été proposée : l’apprentissage de la lecture a modelé certaines aires cérébrales devenues capables de reconnaître des mots ou des structures syllabiques ; en conséquence, nous devons être plus rapide à reconnaître des mots ou des structures syllabiques que des chaînes de consonnes.
- La classe a été séparée en deux groupes selon la série de mesure réalisée en premier :
- mesure du temps de réponse pour des mots
- mesure du temps de réponse pour des chaînes de consonnes
- Suite à ces mesures, chaque binôme devait transférer ses résultats dans un fichier modèle Excel.
Grâce à la réalisation automatique du graphique, les élèves devaient réfléchir à l’exploitation mathématique des données obtenues : moyennes, écarts types, nombre d’erreur / oublis, intervalles de confiance.
- Un bilan écrit devait ensuite être rédigé pour répondre au problème.
- Bilan de cette séance :
Les élèves de première L ont eu du mal à s’approprier le problème et le protocole. De ce fait, lors de la réalisation de ce dernier, les deux membres de plusieurs binômes ont inversé leur place et ce n’est pas le même élève qui a fait la mesure du temps de réponse pour les mots et pour les chaînes de consonnes. Les résultats obtenus n’étaient, alors, pas toujours comparables.
La représentation graphique a perturbé les élèves alors qu’elle était prévue pour aider : la comparaison avec les résultats scolaires a créé un paradoxe car une bonne performance scolaire s’exprime par une note élevée (un point « haut » sur le graphique), alors que dans le test réalisé, une bonne performance s’exprime par une valeur faible (un point bas sur le graphique). Certains élèves ont pâti de cette confusion.
Par la suite, les élèves ont été très dépourvus pour exploiter mathématiquement l’ensemble des valeurs obtenues. Ils se sont beaucoup appuyés sur le nombre d’erreurs et d’oublis, un peu moins sur les moyennes. La notion d’intervalle de confiance n’a pas été vraiment investie.
Les bilans écrits ont été soit très rapidement rédigés sans approfondissement, soit non faits.
Suite à ce travail, la séance a été reprise et les ressources retravaillées pour s'insérer dans une séquence expérimentées en 1°S dans le cadre de l'accompagnement personnalisé.
3- Séance expérimentée en première S
31- Représentation d’une série de données
Le logiciel Réaction présente les temps de réponse sous la forme d’un graphique avec le rang d’apparition des figures en abscisses et le temps de réponse en ordonnée.
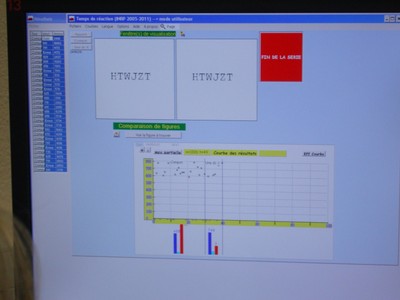
Affichage de l'écran du logiciel Réaction, mesure du temps de réaction face à des séries de consonnes.
- Durant la phase de test en première L, une mauvaise appropriation de la représentation graphique avait été observée, avec des difficultés pour les élèves à comprendre qu’un temps de réaction rapide correspond à une valeur faible et donc basse sur la graphique et non à une valeur haute, et des difficultés à repérer la place des erreurs ou oublis (dans le graphique Excel, ces résultats forment des points sur l’axe des abscisses, comme des valeurs nulles).
Il a donc été demandé aux premières S de réaliser des mesures de temps de réaction et de réfléchir à une représentation graphique avant la phase d’expérimentation sur l’apprentissage de la lecture (Lien vers document utilisé) afin de comprendre que :
- le temps de réaction correspond à une valeur variable et que donc les 40 temps de réaction mesurés sont différents
- qu’une bonne performance correspond à une valeur faible, basse sur le graphique
- qu’un choix doit être fait pour la représentation des erreurs / oublis
Cela a permis en outre :
- d’expliquer l’indépendance des mesures rang à rang et donc l’inutilité de comparer deux séries terme à terme
- de commencer à réfléchir au traitement mathématique des valeurs obtenues

Travail préparatoire sur la représentation graphique.
32- Conception d’un protocole
- Le problème posé était le suivant : « Comment prouver que notre cerveau a développé une capacité à reconnaître des mots ? », associé à l'hypothèse : « Si notre cerveau est devenu capable de reconnaître des mots, il doit mettre moins de temps à reconnaître des mots (ou des structure syllabiques) que des chaînes de consonnes. Nous appelons la valeur mesurée le temps de réponse.»
- Durant l’expérimentation en première L, les élèves avaient eu du mal à s’approprier le protocole expérimental. Il a donc été proposé aux élèves de première S un document présentant le protocole d’une expérimentation réalisée par une équipe de neuroscientifiques pour répondre à la même question mais en utilisant l’imagerie cérébrale fonctionnelle (Cohen et al, 2002). A l’aide de ces informations, les élèves devaient créer leur propre protocole pour éprouver l’hypothèse, en utilisant le logiciel Réaction.
Le travail des élèves a été très productif même si, en raison de la grande liberté que nous avions choisie de leur laisser, les élèves sont rapidement sortis des consignes données et ont cherché à créer des expériences originales mais n’utilisant pas toutes le logiciel proposé. Ce travail a permis aux élèves de très bien s’approprier le problème et l’hypothèse.
33- Réalisation d’un protocole commun : obtention de séries de valeurs
Après cette phase de réflexion, un protocole commun a été proposé. Il avait été prévu que le protocole commun soit conçu par les élèves mais ce choix a été modifié par manque de temps. Les conditions expérimentales ont cependant été discutées en classe.
La mise en œuvre du protocole a ensuite été réalisée par les élèves avec sérieux et dans le plus grand calme.

Réalisation d'une série de mesure.
34- Traitement des données issues de la mesure d’une grandeur variable : quels outils mathématiques ?
- Un fichier Excel avec des pré-traitements a été fourni aux élèves. Il permettait de réaliser automatiquement une représentation graphique et proposait directement notamment le calcul de la moyenne, l’affichage du nombre d’erreurs et d’oublis, et l’identification du min et du max pour chaque série de données.

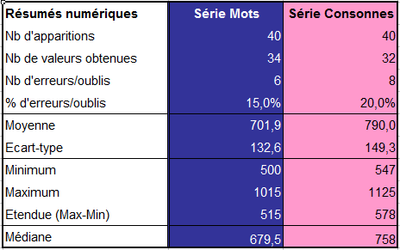
Représentation graphique et résumés numériques obtenus grâce au fichier Excel.
- Presque tous les groupes d’élèves ont proposé de comparer les moyennes pour comparer les deux séries de mesure.
Afin de leur faire comprendre que la moyenne est elle-même variable d’une série de mesure à une autre, nous avons proposé aux élèves de réaliser une deuxième série de mesures pour l’un des tests. Ils ont ainsi pu constater que la deuxième moyenne obtenue était différente de la première. La question s’est alors posée de déterminer si la variation observée entre les moyennes de deux séries de données obtenues dans des conditions différentes provient de la variabilité de la grandeur mesurée, ou de la différence entre les conditions de mesures. Il s’agit de savoir si la différence observée entre les deux tests est significative.
Un autre outil statistique a été présenté aux élèves : l’intervalle de confiance, donnant une estimation de la moyenne du temps de réponse à partir de la série de mesures obtenue (voir 4). Un onglet du fichier Excel calculait automatiquement les bornes de l’intervalle de confiance de chaque série de mesure, et en proposait une représentation graphique.
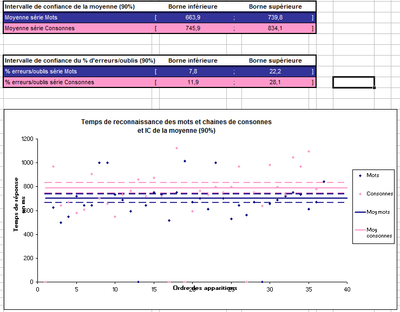
- Avec tous ces éléments, chaque binôme a du produire un premier bilan de
l’expérimentation dans un onglet réservé du tableur.
35- Présentation orale du bilan de l’expérience
- Durant la dernière séance, les élèves ont élaboré une présentation Power Point en travaillant à deux binômes regroupés, et l'ont présenté en 5-10 minutes aux autres élèves et professeurs présents dans la salle ainsi qu’à
Mme Fontanieu, statisticienne de l’IFE. Cette étape s'ancre ainsi pleinement dans les objectifs des nouveaux programmes. Ceux-ci préconisent effectivement échanges et débats entre élèves afin de développer les qualités d'expression, d'écoute et de respect mutuel (BO spécial n°8 du 13/10/2011). Ces échanges contribuant à construire une notion commune à partir des résultats et expériences de chacun. Enfin, ce type de communication permet de travailler la création / production de données numériques conformément aux objectifs du B2i lycée (MENE0601490A / Arrêté du 14/6/2006 / J.O du 27/6/2006).

Présentation orale des résultats par un groupe.
- Les deux heures imparties ont été bien utilisées. Les
élèves se sont questionnés sur les données à utiliser, sur la manière de les
représenter, et sur les indicateurs statistiques à mobiliser pour leur
argumentation. La phase de présentation a été l’occasion d’une discussion à
l’échelle de la classe sur ces différentes questions. Elle a également révélé
la façon dont les élèves s’étaient appropriés ou non les modalités de
représentation graphique et les notions statistiques proposées (Monod-Ansaldi et col, TICE2012, 277-282). En particulier,
la notion d’intervalle de confiance n'a pas été complètement appropriée par les élèves.
36- Utilisation des protocoles imaginés pour réaliser des jeux intelligents.
Afin de valoriser le travail de création de protocole réalisé lors de la première séance, les élèves ont profité de la dernière heure d’accompagnement personnalisé pour réaliser par binôme des jeux intelligents mettant en évidence la capacité du cerveau à lire et à comprendre un mot ou un texte.
4- Approche statistique de l'étude du temps de reconnaissance de mots et non-mots :
Au cours de cette expérimentation les élèves ont travaillé à la planification et la réalisation d’une étude statistique. Un certain nombre de notions de statistique ont ainsi été investies.
- Pour commencer une hypothèse était formulée : il faut plus de temps pour reconnaitre les non-mots. Les élèves ont alors été amenés à réfléchir au protocole expérimental à mettre en œuvre pour recueillir des données, les traiter et les analyser afin de tenter de répondre à la question de biologie soulevée et d’éprouver l’hypothèse formulée.
- Le temps de réaction pour un même individu étant une grandeur qui fluctue, son étude nécessite le recueil d’un échantillon de mesures.
L’expérience menée consistant à comparer les temps de reconnaissance pour la comparaison de mots (test mot) et pour la comparaison de non-mots (test non-mot), les élèves devaient ainsi recueillir deux échantillons de leur temps de réponse, un pour chaque test. Afin qu’aucun autre facteur ne puisse être suspecté d’influer sur les résultats, l’organisation du recueil des deux séries de mesures devait permettre une réalisation dans des conditions identiques, compte-tenu des possibilités envisageables dans le cadre de la classe. Pour cela notamment, un entrainement préalable était prévu pour éviter que la première série soit « désavantagée » par rapport à la deuxième par un effet d’entrainement, les élèves devaient être installés de la même façon pour les deux tests et sur le même ordinateur, les deux séries devaient être recueillies le même jour (même état de vigilance), les deux tests ne devaient varier que par les « formes » à reconnaitre (même intervalle de temps pour l’apparition des formes, même nombre de formes parmi lesquelles tirer aléatoirement une forme). A propos du nombre de mesures à recueillir un compromis, entre un nombre suffisant pour un traitement statistique (considéré supérieur ou égal à 30) mais pas trop élevé pour éviter de provoquer fatigue et perte de concentration, a conduit les élèves à réaliser des séries de 40 mesures.
- Une fois les données recueillies avec le logiciel puis renseignées dans le tableur Excel, les élèves ont pu procéder à leur analyse.
Une représentation graphique simultanée des deux séries de données (nuage de point avec en abscisse le rang d’apparition dans la série et en ordonnée le temps de réponse des deux séries) a donné une première approche de la distribution des valeurs. On peut souligner que les deux séries ne sont pas appariées c’est à dire que l’observation de rang x de la série test mot n’est pas liée à l’observation de rang x de la série test non-mot. Les graphiques de représentation des données (histogrammes, nuages de points, boxplot, …) permettent d’appréhender visuellement la distribution des valeurs (plus ou moins grande variabilité, valeurs atypiques, « position » d’une série par rapport à l’autre…). Les élèves ont ensuite pu lire dans le tableur, différents résumés numériques de leurs séries de données (min, max, étendue, moyenne, écart-type, médiane, nombre d’erreurs, nombre d’oublis), leur donnant cette fois des indicateurs descriptifs de leurs séries de données. On peut noter que les erreurs et les oublis rendaient le nombre de valeurs observées inférieur ou égal à 40. La réalisation d’une deuxième série pour un même test a contribué à s’apercevoir qu’en raison des fluctuations d’échantillonnage une autre série de mesures, réalisée dans les mêmes conditions, donne lieu à une autre estimation des indicateurs.
- La mobilisation d’outils de comparaison a conduit les élèves à se demander « à partir de combien peut-on conclure à une différence significative ? ».
La notion de test statistique a alors pu être abordée, et la méthode proposée a consisté à comparer les intervalles de confiance (IC) des moyennes des deux séries. La comparaison des IC a été préférée au test d’hypothèse (méthode comparable mais plus élaborée permettant de quantifier la probabilité de rejeter à tort l’hypothèse, appelée erreur de première espèce) car plus facile à comprendre.
L’intervalle de confiance de la moyenne (µ) au niveau de confiance 1-α = 90% (α étant souvent choisi égal à 1%, 5% ou 10%) est l’intervalle de valeurs, estimé à partir d’un échantillon, tel que la probabilité que la moyenne théorique (µ) soit comprise entre les bornes de l’intervalle est égale à 0.90. Si l’on reproduisait de nombreuses fois l’expérience, 90% des intervalles obtenus contiendraient la valeur µ. Cet intervalle, centré autour de la moyenne, varie en fonction de la variance de l’échantillon et du nombre d’observations. La comparaison des deux intervalles obtenus conduit à rejeter l’hypothèse d’égalité des moyennes des deux séries lorsqu’ils ne sont pas chevauchants et à ne pas rejeter l’hypothèse lorsqu’ils sont chevauchants.
- Plusieurs autres éléments de comparaison des séries ont été suggérés, en tant qu’indices supplémentaires pour éprouver l’hypothèse formulée.
En particulier une plus grande difficulté à reconnaître les formes, outre le temps de réponse plus long, peut se manifester par une plus grande dispersion des temps de réponse (test de comparaison des variances) ou par des erreurs et oublis plus fréquents (test de comparaison des proportions d’erreurs/oublis). Par ailleurs la pertinence d’une étude de l’ensemble des données de la classe vues comme un échantillon d’une population plus grande a été évoquée avec les élèves (analyse simultanée d’un effet élève et d’un effet « mot / non-mot »).
5- Analyse didactique
Une analyse de la séquence a été présentée au colloque TICE 2012 ( (Monod-Ansaldi et col, TICE2012
, 277-282).
- Dans les séances de TP classique, le manque de temps nous conduit souvent à faire des raccourcis pédagogiques :
- protocoles non réfléchis par les élèves et imposés de ce fait par le professeur, la réalisation de ceux-ci par les élèves peut alors être plus ou moins sérieuse car incomplètement investie
- analyse parcellaire des résultats, en particulier lorsqu’ils sont chiffrés, par la mise à l’écart des résultats déclarés aberrants, la réalisation de moyennes plus ou moins corrigées (élimination de valeurs aberrantes par exemple).
- communication par écrit via un compte rendu de TP stéréotypé et écrit
- proposition d’un corrigé unique
L’enseignant prend ainsi une place prépondérante dans la démarche expérimentale, le rapport est linéaire et hiérarchique ; le savoir est détenu par l’enseignant qui le transmet à l’élève. Le rôle de ce dernier se limite le plus souvent à manipuler dans la voie qui lui a été demandée sans discussion ni autonomie.
- Dans le cas de cette démarche, l’élève a été placé au cœur de la réflexion :
- conception du protocole, même si le protocole réalisé a été en partie imposé, il a été demandé aux élèves de réfléchir aux conditions expérimentales
- exploitation mathématique des données obtenues de manière approfondie, outils fournis au fur et à mesure
- communication orale en groupe, chacun choisissant les outils utilisés pour répondre à la problématique
- aucun résultat écarté, aucune conclusion imposée. La diversité des résultats a au contraire été l’occasion de discuter
- Cette liberté, relative a créé une grande émulation pour les élèves. Comme par ailleurs, le sujet traité est encore en cours de recherche, le travail a été considéré comme plus « sérieux ». Ce dernier point est également important car les élèves avaient moins peur de se tromper puisqu’en l’état actuel, les connaissances n’ont pas permis d’avancer un dogme sur le rôle complet du cerveau dans l’apprentissage de la lecture et l’impact de cet apprentissage sur le cerveau.
Le ressenti des élèves a d’ailleurs été qu’ils avaient l’impression de réaliser une « vraie » expérience en ayant particulièrement apprécié le temps qu’ils avaient pour réfléchir, réaliser…
- En dernier lieu, la réalisation d’une présentation orale devant un tiers, l’outil Power Point ayant été imposé, s’ancre dans la réforme du lycée. Elle a permis a chacun d’utiliser les outils que les élèves avaient ou pensaient avoir acquis.
Lors de la séance de cours associée à ce TP, les différentes idées qui étaient sorties de la réflexion des élèves ont pu être réinvestie. La plupart des groupes avaient des résultats ne prêtant guère à confusion. Cependant, un groupe avait des résultats totalement inverses aux autres groupes. Cela a conduit les élèves à se poser davantage de question sur ce qu’on appelle « scientifiquement prouvé » et aussi à comprendre la composante individuelle du fonctionnement de notre cerveau.
- Au final, l’investissement des élèves a été très encourageant, les résultats et les productions obtenues ont permis d’avancer dans le cours mais aussi dans la compréhension des notions statistiques utilisées, aussi bien pour les élèves que pour le professeur.
La séance produite est maintenant bien finalisée et pourrait être utilisée avec d’autres élèves par d’autres professeurs.
Bibliographie :
Cohen, L. Lehiricy, S. Chochon, F. Lemer, C. Rivaud, S. Dehaene, S. (2002) Language specific tuning of the cortex ? Functional properties of the visual word form area. Brain, 2002, Oxford University Press, Vol. 125, pages 1054-1069
Bentin, S. Mouchetant-Rostaing, Y. Giard, M-H. Echallier, J-F. Pernier, J. (1999) ERP manifestations of processing printed words at different psycholinguisitc levels: time course and scalp distribution. Journal of Cognitive Neuroscience 11:3, pages 235–260
Mc Candliss, B-D. Cohen, L. Dehaene, S. (2003) The visual word form area: expertise for reading in the fusiform gyrus. Cognitive Sciences Vol.7 No.7 July 2003, pages 293-299
Dehaene, S. (2007). Les neurones de la lecture. Odile Jacob
Girault, Y. & Girault, M. (2004). L’aléatoire et le vivant. Les presses de l’Université de Laval.
Monod-Ansaldi, R., Cordier, F., Fontanieu, V. et Daubias, P. (2012). Outiller l’approche statistique des résultats en SVT : retour d’une expérimentation sur les temps de reconnaissance de mots en 1°S. Actes du Colloque TICE 2012, Lyon. pp277-282.
Palliera, C. Devauchelle, A D. Dehaene, S. (2010) Cortical representation of the constituent structure of sentences. www.pnas.org/cgi/doi/10.1073/pnas.1018711108
Price, C-J. Wise, R-J-S. Frakowiak, R-S-J. (1996) Demonstrating the implicit processing of visually presnsented words and pseudowords. Cerebral Cortex Jan/Feb 1996; Vol 6 ; 62-70; 1047-3211
Tarkiainen, A. Helenius, P. Hensen, P-C. Cornelissen, P-L. Salmelin, R. (1999) Dynamics of letter string perception in the human occipito temporal cortex, Brain, 1999, Oxford University Press, Vol. 122, pages 2119-2131
Pages du site Acces en relation avec ce thème :
Reconnaissance des mots et plasticité 1
Reconnaissance des mots et plasticité 2
Reconnaissance visuelle des mots




